반응형
Ascii to Unicode 변환 (Codepage 별로 정리)
많은 사람들이 ascii에 그냥 00붙는 거 아니냐? 하곤 한다.
- ex) 0x01 --> 0x01 0x00
- ex) 0x0a --> 0x0a 0x00
절반만 맞다.
int MultiByteToWideChar(
UINT CodePage, --- 어떤 unicode로 변환할래?
DWORD dwFlags,
LPCSTR lpMultiByteStr, --- 변환 할 문자열이 담긴 곳
int cbMultiByte,
LPWSTR lpWideCharStr, --- 변환 결과 문자열이 담길 곳
int cchWideChar
);
ascii -> unicode로 변환은 MultiByteToWideChar 함수를 통하는데,
여기서 CodePage에 따라 어떤 유니코드로 변환될 지가 결정된다.
즉, CodePage 값에 따라 Ascii -> Unicode 변환 결과가 달라진다는 말이다.
CodePage 인자만 별도로 나열해 보자.
| Value | Description |
| CP_ACP | ANSI code page |
| CP_MACCP | Not supported |
| CP_OEMCP | OEM code page |
| CP_SYMBOL | Not supported |
| CP_THREAD_ACP | Not supported |
| CP_UTF7 | UTF-7 code page |
| CP_UTF8 | UTF-8 code page |
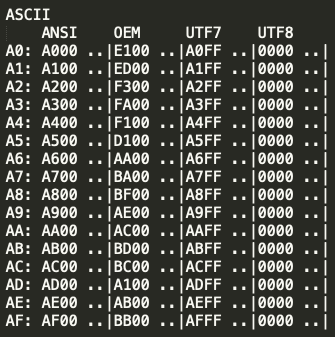
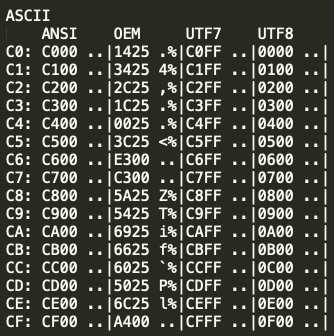
아스키는 7bit로 문자를 표현한다. (범위 : 0~127 == 0x00~0x7f)
따라서 아스키로 표현 가능한 문자는 ascii 그대로에 00만 추가로 붙는다. (일반적으로 많이 알고 있는)
0x00 0x00 ~ 0x7f 0x00
하지만 0x7f를 초과 범위부터는 어떤 유니코드냐에 따라서 달라진다.
표로 정리한다. (표로 넣으려 했더니 너무 번거로워서 그냥 텍스트 캡쳐해서 올린다..-_-)
SEH Unicode 등에 적절하게 상황에 맞게 참조하자.














반응형
'취약점 분석 > SEH Unicode' 카테고리의 다른 글
| [Anyburn 4.3 x86] SEH Unicode Exploit 분석 (0) | 2020.01.06 |
|---|
